最近要开始写《孟子》的课程论文了,但选题令人头疼。如果已经想好了一些关键词,我们都知道可以在《孟子》原文word中直接查找其出现了多少次,以及高亮显示其所在位置。那么如果确定要写这个关键词,就比如说”仁”吧,怎样把有”仁”字的段落全部摘出来以便更好地分析呢?
用通配符可以很轻松地解决这个问题。我们的目标是达到下图这个效果(公式可能看不清,大家可以先动脑想一下如何实现),然后就可以把含”仁”的70个段落全部粘贴出来了:
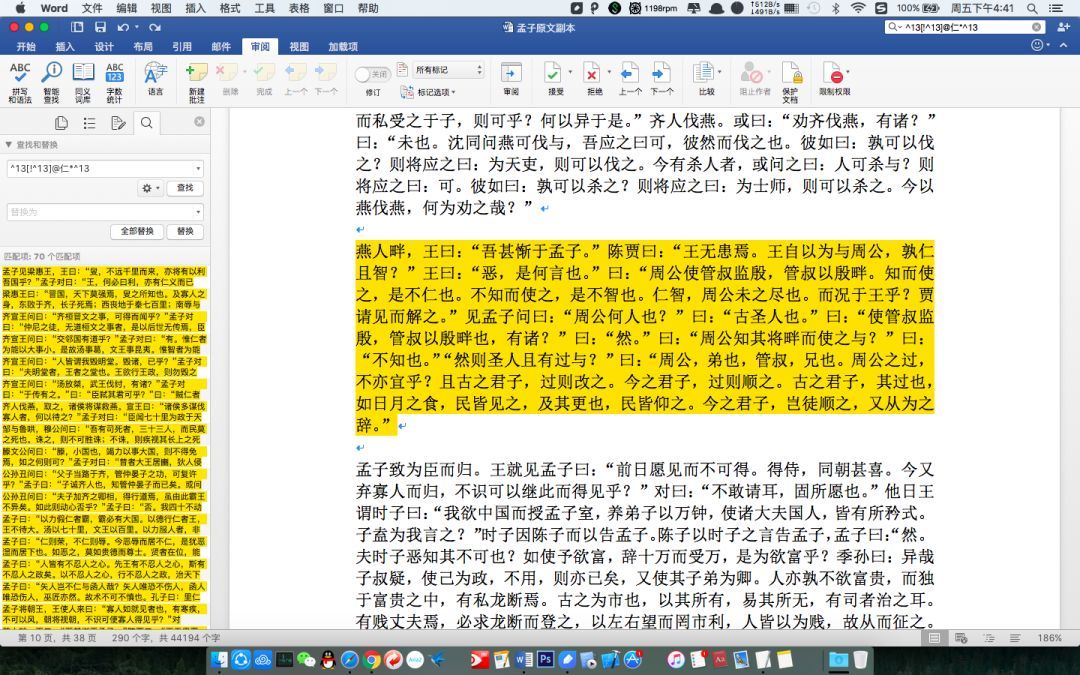
直接报答案吧:勾选”使用通配符”选项: ^13[!^13]@仁[!^13]@^13(关键词在段落中间时)
这个公式中把”仁”字换成其他任何关键词都可以,如果要查找到以”仁”开头的段落,再另外搜索 ^13仁[!^13]@^13 即可;如果要查找到以”仁”结尾的段落,则搜索 ^13[!^13]@仁^13。
解释一下思路:
^13表示段落标记(不使用通配符则用^p),因为原文本中每一小段之间都有换行,所以用^13开头和结尾,表示寻找在两个换行符之间的文本。
[!^13]则表示除了段落标记以外的任何单个字符,其中!是”非”的意思,中括号表示指定范围。正因为每一个[!^13]只占一个字符,所以我们要用@表示重复前者无数次。
连起来看,^13[!^13]@表示换行符之后有多个不是换行符的字符,然后紧接着”仁”,也就是我们的关键词(注意:我们的关键词在段落开头的情况会被忽略)。[!^13]@^13也是同理。
PS:大家可以试试把公式中的[!^13]@换成*,这样的话会匹配到该关键词段落的前面多个不包含此关键词的段落,因为*也会匹配到段落标记,这会造成查找结果的混乱。